In 2017, design cycles move faster, and target audiences are more diverse and widespread than ever before. At the same time, we have an ever-increasing need for research. While this is great for job security, it also presents some challenges. For instance, budget and recruiting speeds don’t always improve at the same pace as our design cycles or our need for research.
We’ve heard the following problem discussed several times: A design team faces a brand-new research question and could really use some insights from niche target users before the end of their design sprint. However, the recruiting process alone will not complete until close to, or after, the end of their sprint.
While there are several solutions to this problem, many practitioners long for a solution that enables them to recruit for, and complete, a spontaneous ad-hoc research project, all while fitting budget, deadline, and recruitment needs.
It wasn’t until we attended Marc Schwarz’s “Mechanical Turk Under the Hood” talk at UXPA International Conference in 2016 that we seriously considered Mechanical Turk as a solution to this problem.
After a year of constantly experimenting and integrating Mechanical Turk into our process, we went back to the UXPA International Conference in 2017 to discuss our experience with a tool that we now find to be a powerful, low-cost, internationally reaching, scalable, and fast solution.
What Is Mechanical Turk?
For those who are unfamiliar, Mechanical Turk is an Amazon offering that is marketed as access to an on-demand, scalable workforce. Those hoping to leverage this workforce can simply post a Human Intelligence Task (HIT), and people around the world (known as “Workers” or “Turkers”) are able to complete the task for some amount of compensation determined by those requesting the work.
The types of HITs include, but are not limited to, transcription, data collection, image tagging/flagging, writing, and answering surveys. Amazon uses the term “Artificial Artificial Intelligence” to describe Mechanical Turk, as its primary goal was to facilitate tasks that were difficult for artificial intelligence (AI) to perform by offloading the tasks to real people, or Workers.
Researching with Mechanical Turk
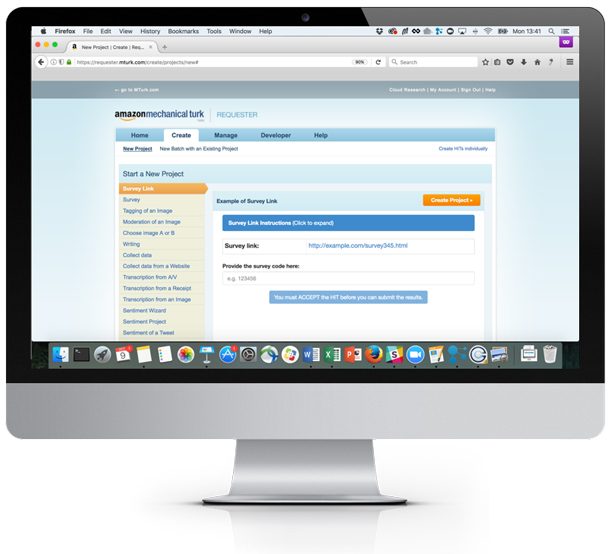
One thing that should be made clear up front is that while Mechanical Turk is in no way a full-fledged user research platform, it can be linked to one. As can be seen in Figure 1, a variety of HIT types are available, but our team has relied on only one to accomplish a wide range of research activities, and that is the Survey Link option.
As you aren’t truly limited to linking Workers to just surveys, this option essentially acts as a link to any research or testing platform you may already be using. For example, while our team has primarily linked Mechanical Turk to surveys, we have also successfully sent Turkers to Optimal Workshop to accomplish a card sorting exercise to test the information architecture of one of our offerings.
Benefits of Researching with Mechanical Turk
It didn’t take us long to realize the potential upside of this tool after some initial pilot studies. We got up and running with some surveys and were immediately impressed with the results.
International reach
Our company designs products that are to be used in markets internationally, but we had previously struggled with finding many research participants outside of North America who met our target demographic. Although a slight majority of Mechanical Turk Workers are located in the US, the platform is a great way to reach an international audience and find a lot of variation across several demographics. Soon after launching our first study, we were getting responses from across the globe.
Scalability
After a couple of smaller pilot studies, we wanted to see just how many target users we could find on this platform. The verdict: It’s really easy to scale up studies with this platform. Thousands of Workers can be reached for a given study, which helped us screen large enough groups of participants for entire qualitative studies, and also enabled us to achieve statistical power when desired.
Most of our early studies required tens or hundreds of participants to complete, yet we usually finished data collection in a day or two. Since our initial use, Mechanical Turk has continued to be a go-to platform when we need immediate results for research questions.
Low cost
Budget wasn’t one of our top recruiting concerns at the time, but we felt pretty good knowing that we could conduct research on a low budget. Recruiting fees on the platform are fair (20% of the incentive for N ≤ 10; 40% of the incentive for N > 10) and the average incentive cost is low. Some activities pay only cents per completion. Despite this, we try to follow local incentive norms rather than taking advantage of the low incentives on the market.
Biggest Challenges Faced and How We Overcame Them
Although the platform has numerous unique strengths, our experiences with Mechanical Turk haven’t exactly allowed us to sit back and relax. We discovered a lot of challenges that required careful consideration and clever techniques to mitigate.
Low-quality responses
Unthoughtful, brief, and dishonest responses were constantly a problem when we first started out. We began requiring word count minimums and only publishing activities to Workers with 95% approval ratings and higher. It wasn’t a perfect solution, as we still had some issues, but they were usually a lot easier to spot and much less frequent.
“Friends? I work in IT. The only friends I have are here and we try to talk about anything but it.” (Worker, faking a response after being asked to describe their job as if speaking to a friend)
The main reason for a lot of the problems we faced is that many Workers are on Mechanical Turk for extra cash and are likely to speed through multiple HITs quickly to maximize their profits. To alleviate that, we started offering bonuses for thoughtful responses.
“Hello Dear Sir or Miss, could you pay me please? I need the money to buy something. Thank you.” (Worker, awaiting payment)
Shared answers on public forums
Workers frequently communicate with one another on several forums and Reddit. After doing some searching, we found that we were part of some discussions, which gave us unwanted attention. For example, at least one Worker was actively trying to get through our screener and share results with the community. To our benefit, they couldn’t figure it out and assumed that our study was broken. Publicity is generally not a good thing when trying to hide what you are truly screening for. We’ve since learned to avoid posting publicly when possible, offering too large of incentives (publicly), or offering too many HITs at once, as these can attract unwanted attention.
Finding Our Target Users Through Screening
As we had noticed that participants were able to reverse-engineer the “right” answers to get through our screeners more easily than we would have liked, we went to great lengths to give zero indication as to what we were looking for. In a perfect world, all respondents would answer screener questions honestly, but this often is not the case when the monetary incentive is the primary motivator. With this in mind, we wanted to try to make it harder for them to guess their way into qualifying for our activities. While this is a common goal when screening, to accomplish this we had to get a little more creative with this particularly persistent participant pool.
Open-ended questions
We originally began relying more on multiple-choice questions, which are much easier to guess or luck your way through. Once it became obvious that this wouldn’t suffice, we started looking to leveraging more open-ended questions. One particularly successful way we managed to screen participants out by job title was to simply ask participants to provide their job title in an open-field question.
While this would be easy enough to go through manually with a smaller sample size, we needed a way to automate the screening as we scaled up, so we managed to come up with a little clever logic on the back-end. SurveyGizmo allowed us to qualify or disqualify based on whether or not an open-ended answer contained a number of word strings; that way we simply disqualified any answer that didn’t include any of the job titles we were interested in. As shown in Figure 2, participants see no indication as to what we are looking for.
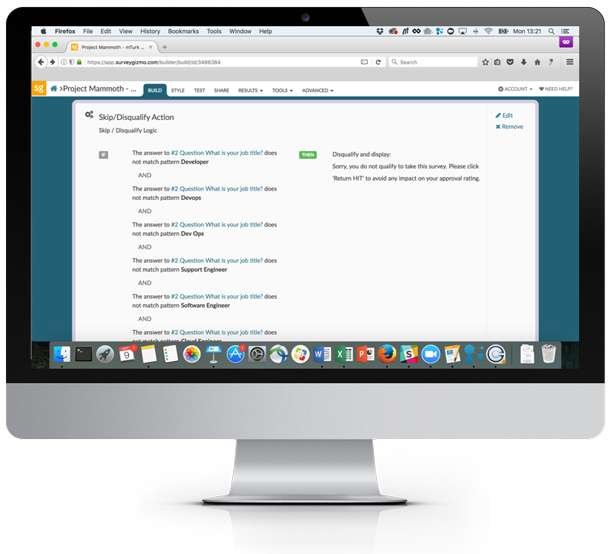
Our solution was to build in a good deal of logic, which can be seen in Figure 3. While this sounds simple enough, we discovered it took quite a bit of iteration to ensure we weren’t screening out anyone we actually would like to take part in our research. There are likely a variety of titles that you may overlook, but you can always add and iterate on your list of logic.
Knowledge probes
We also relied on open-ended questions to act as knowledge probes to ensure participants weren’t just lucking their way into our study. This turned out to be an effective way of determining who was actually a good fit for our study, or more importantly, who was not. While it became fairly easy to quickly screen out the duds, we did find that this measure didn’t lock out all the fakers.
Although we were relying on some of the automated screening logic, we still did manual reviews to ensure that no one got through who shouldn’t have. One day while doing this we discovered two identical answers to one of our knowledge probes. The question asked participants to explain a particular topic in their own words, and it turned out two participants had used the same exact words. After a quick Google search, we discovered both of these participants had Googled the topic and pasted in one of the first explanations they had found.
After this discovery we were able to adapt an approach similar to the one we took for screening based on job titles. Whenever we used one of these types of knowledge probe questions, we would do a couple of Google searches around the topic to collect snippets of explanations and include them in the screening logic for the open-ended knowledge probe. Surprisingly, this method caught a number of people.
Creative use of multiple choice
While we had shifted toward using more open-ended screener questions, we didn’t drop multiple choice completely. This too has been an effective tool for screening out the fakes for us. One particular implementation of a multiple-choice question that has become a staple in our screeners revolves around the tooling participants use. We ask participants to select from a list of tools to indicate the ones they are using, but we include a few red herring answers that aren’t actual tools. You would be surprised how many fakers this tooling question disqualifies from your activity. We attribute this to the number of oddly named tech tools out there these days.
Motivating Participants Through Qualification Surveys
Using these screening techniques, we’ve been able to screen out thousands of participants to get to a subset of a few hundred target participants. One useful feature of Mechanical Turk is its qualification surveys, in which you offer to pay a low compensation to all who participate, regardless of whether or not they qualify, with the promise of high-paying activities in the future for those who do qualify. You can do this instead of offering a large amount only to those who qualify while you screen out a number of participants who receive no compensation in the process. We’ve found that promise of getting access to higher paying surveys has been an effective incentive to get participants to take these qualification surveys.
Qualified user panels for quick launches
Through the use of these qualification surveys you are able to start creating groups of Workers that have already been deemed fit for your research studies. Once you have these established panels, it becomes much easier to quickly launch to a group you are confident matches your qualifications. One thing to note with the use of panels is the question of retention. We have experienced some issues where we launched to one of these panels and did not get the response rate we were hoping for. There appears to be some level of churn that has to be accounted for, so you will want to continually grow and curate your panels to avoid this low response rate.
Policies We Created Along the Way
Over time, we’ve formed policies to help improve our research methods, ethics, and data quality when using Mechanical Turk. Here’s a list of our top takeaways:
- When in doubt, approve Worker submissions. Rejections hurt a Worker’s status. It’s usually easier to simply remove the data and/or the person from your panel.
- Never ask for personal identifiable information from a Worker, as it violates Mechanical Turk policy.
- Publish to Workers with high approval ratings (95% and higher) rather than requiring Master Workers, to increase data quality without substantially sacrificing scale.
- Keep screeners as vague as possible so people can’t possibly guess what you’re looking for. Otherwise, clever cheaters will reverse-engineer your screener and complete studies they are unqualified for.
- Don’t pay too little, but be cautious about publishing public HITs with high incentives as they draw unwanted attention from cheaters.
- Where possible, incentivize thoughtful and honest responses by offering Grant bonuses.
- Keep a database outside of Mechanical Turk for panels and Worker data. Protect the data as though it includes identifiable information.
- Modify your survey link using custom code to mask the link until it is accepted and to send Worker IDs to your survey tool. (https://research-tricks.blogspot.com/2014/08/how-to-transfer-mturk-workers-ids-to.html.) This increases security by preventing Workers from attempting your screener before accepting the HIT. Also, when sent to your survey tool, Worker IDs can be used for payment processing and to prevent duplicate attempts.
- Use automation to screen out masked IP addresses, duplicate or blank Worker IDs.
- Closely monitor activities and provide Worker feedback when they reach out. We use an integration so that every Worker email is automatically responded to and updates our researchers in a Slack channel.
- Since you cannot ask for contact information, use bonuses to follow up with a Worker (for example, $.01 and a message about a research activity, followed by another bonus for their incentive).
The Evolution of Our Usage
When we first started out, we recruited a lot of IT Workers and subject matter experts for various studies and panels. Overall, we were pretty successful at that. If we came across a research question and needed fast insights or a large sample size, we could usually rely on Mechanical Turk to get the job done. We’d continuously increase the size of our panels such that we’d have participants on-demand at any point in the design cycle and could feasibly get lightning fast results for most studies.
Since then, however, our usage of Mechanical Turk has shifted a little bit. As a result of our learning and the continuous improvement of our tool chain, we now leverage it without as high a regard for subject matter expertise as before.
Perhaps even more interesting is our newest use case, which takes advantage of our ability to reach such a diverse and broad audience. We’ve surveyed thousands of Workers about their physical and cognitive abilities. Since collecting this data, we have had the ability to publish studies to pre-qualified participant panels with varying abilities, enabling us to ensure that we are designing more accessible products.
Despite our changing needs, the scale, diversity, speed, and cost of Mechanical Turk offer so many potential uses that we have found innovative ways to integrate it into our process regardless of what else exists in our tool chain. Mechanical Turk has brought us closer to our enterprise software users by enabling us to fit unmoderated research into our quick development cycles, reach new and international audiences, and leverage large panels of prequalified target users.