In April 2017, the University of Texas at Austin hosted the First Annual Workshop on the Science of UX. The theme of the workshop was “Making Small UX Data Big.” The goal was to examine the possibility of building and curating a clearinghouse of usability and UX findings that would ultimately inform the selection of UX methods used for a particular project.
Moore’s Law characterizes the geometric advances afforded us by technology. These advances are of no value if the user cannot figure out how to use them. In 2014, Bias, Lewis, and Gillan wrote about how the glacial pace of human evolution, in comparison to the engineering-based advances in technology, should motivate more (year on year) attention to the human user in any human-computer interaction. In 2016, Randolph Bias attended a talk by Dr. Kerstin Lehnert at the University of Texas at Austin Jackson School of Geosciences. Dr. Lehnert discussed her three-year effort to “make small data big.” Her approach was to develop a clearinghouse for sonar, soil sample, and other data to help the entire field of petro-sciences drill for oil below the oceans more intelligently, empirically, efficiently, and safely. If every “cruise” that collected sample data entered it in a usable fashion into a single database, and shared it with others, well then, a rising tide raises all ships, and it would benefit all the contributors. What is the motivation for for-profit companies to share the data they’ve paid to acquire? Of course, it would be the opportunity to enjoy the benefits of the data shared by others.
The field of usability/UX is a tremendously valuable pursuit. The return on investment (ROI) for any dollar spent on usability is usually positive and robust. The biggest weakness of the field is the low barrier to entry. The most serious concomitant issue, we humbly assert, is the lack of empirical knowledge about which usability engineering method to use and when to use it.
While it is relatively easy to teach a novice how to conduct a specific usability engineering method, there is little knowledge about which method to employ or when to employ it. While experienced usability/UX professionals are likely make good choices about which method to employ—for example, heuristic evaluation, survey, usability walkthrough, end-user testing, contextual inquiry, or task analysis—at a particular stage in the development of a particular type of product, there is precious little empirical data to address that question. If we can help answer that question with an answer steeped in reliable research, we reasoned, we will help advance our field.
Our vision was to emulate Lehnert’s approach (with her expressed approval) and build and proffer a database of usability practice data. We intend to build a database, and an easy-to-use interface to that database, that can serve as a clearinghouse for the glut of “small” data on user interface design and development. The database would include [data] fields such as:
- Size of the target UI being tested
- Release number (1, 2, etc.)
- Amount of usability work done on the previous release
- Amount of redesign of the UI for new release
- Amount of customer support burden for the current release
- Type of product (for example, e-commerce website, information-only website, transactional web site)
- Usability expertise available to work on this release
- Access to representative users
Twenty UX practitioners, managers, and researchers from around the world interested in advancing the science of UX responded to our invitation to participate in the workshop. (The participants are listed at the end of the article.)
Workshop Process
The workshop followed a “lean agenda” where the problem of missing empiricism in choosing usability evaluation methods was described.
The first step was to identify the questions to be addressed by the workshop. These included:
- What might the “primitives” be (for example, type of product, release number, amount of customer support burden on earlier releases)?
- Would individual UX practitioners (and their supporting organizations) be well motivated to participate in such an effort?
- Would those people have enough ROI data (even estimates, or self-report of “project was a success”) to afford correlational data to drive conclusions about which methods (in particular contexts) were associated with success?
- Does this approach have any hope of success?
The second step was to present a literature review comparing approaches for usability evaluations. Two major challenges of empirically evaluating usability approaches on a meta-level exist:
- The often-cited evaluator effect (demonstrated by Rolf Molich’s CUE Studies), where teams of usability professionals evaluate the same product at the same time but report different issues.
- The common mixing and appropriating of usability evaluation methods in practice, which results in low validity of studies trying to compare two formalized methods directly.
The third part of the workshop was an open discussion among all attendees. Over the course of this discussion, two individual approaches proffered to address the problem of lack of empiricism were identified by the group.
The first proposal focused on transferring existing knowledge from research to usability practitioners. The second proposal was to advance knowledge about usability methods by “making small UX data big.” Subsequently, both proposals were explored in smaller focus groups. Attendees joined their preferred focus group depending on their individual interest and expertise. One of the groups explored the means of supporting novice usability professionals in their choice of appropriate evaluation methods.
The second group discussed which factors influence the successful application of usability evaluations and how success could be measured. These two key questions evolved from the underlying idea of “making small UX data big” and drove the concept of building a collective database of usability evaluations. The database is intended to serve as a basis for future empirical research about what combination of UX methods would be best to use in real-world situations. Within this context the group identified that the following categories of independent variables need to be considered when classifying any usability approach:
- Product information (Maturity, Type …)
- Project details (Budget, Time, Person-hours…)
- Evaluator information (Experience, Number…)
- Usability Method (Survey, Cognitive Walkthrough, Treejack, End-user test…)
- Industry analysis (Competition, Development cycles…)
- User profiles and demographics (Expertise, Age…)
- Motivation for the Test (Formative, Summative, Comparative, or Informative)
Additionally, the group felt that all dependent variables used to judge the success of any individual usability approach should address the variables for usability offered by the International Organization for Standardization:
- Effectiveness
- Efficiency
- Satisfaction
While effectiveness and efficiency enjoy no widely agreed upon metrics, satisfaction can be quantified more easily. Various benchmarks exist to measure a user’s satisfaction and the likelihood to recommend a product. The most prominent metric is the System Usability Scale (SUS), which has two main advantages:
- Flexibility – It can be used to rate a broad variety of products
- Proven validity – It has been used across domains and on a large number of studies
Therefore, the SUS was identified to be part of a minimum viable product.
The workshop was concluded with a presentation to all attendees of the results from both focus groups.
Creating UXChart
During the workshop, one team was tasked with envisioning a survey front-end that would be used by UX researchers to collect data about the products they are testing. These data would be used for two purposes:
- By the UX researchers to inform their product research
- By the Data-Cube (see below) for its “big” analytics
While brainstorming the design of the survey system, there were as many favorite surveys and crucial post-test questions as there were workshop participants, and controlling scope quickly became important.
Scope was controlled by choosing instruments that met the following criteria:
- Have a broad appeal for UX researchers
- Have face validity and combine to form a compelling whole/construct that would be useful for UX research
- Can be implemented with the limited resources of a volunteer workforce
It was clear that the database would not have any data if UX researchers did not use the tools for their own research, so choosing metrics that were useful to researchers was a high priority. SUS was the first metric to be selected. The Net Promoter Score was included because it has broad appeal. Finally, ISO 9241 was used to inform the creation and inclusion of three Likert-scale questions: one each for effectiveness, efficiency, and satisfaction.
During the month following the workshop, Scott Butler designed and implemented an online version of this app, called UXChart. UXChart is a free site that enables UX researchers to administer the required questionnaires to participants and generates a dashboard as shown in Figure 1.

The data summary displays the “small data” that are collected for an individual UX researcher’s user-centered activity, such as a usability test. UXChart would then be used to aggregate and anonymize the data from multiple activities on multiple projects to enable the prototype app Data-Cube to “make it big.”
Workshop participants identified two “big” questions that could be answered by this data set.
- Insights into UX approaches offered by the Data-Cube (discussed in the next section)
- Comparative benchmarks offered by UXChart (discussed in the next paragraph)
Comparative Benchmarks Offered by UXChart
UX researchers who use UXChart are asked to provide two pieces of metadata about each study: industry type (for instance, medical, telecom) and product type. Once UXChart’s data set is sufficiently large, researchers can utilize these metadata to obtain suggested answers to questions like, “What does the Usability Scorecard look like for mobile apps in the insurance industry?” A sample draft of a UI that permits visualization by industry is shown in Figure 2.

Creating Data-Cube
Motivated by the results from the workshop, specifically requirements for building a collective database of usability evaluations, Tobias Eisenschenk built a prototype app called Data-Cube. The purpose of Data-Cube is twofold: It offers an empirical basis for recommending which UX methods to use for a project and when to use them. Additionally, it provides an easy-to-use interface for contributing to the dataset.
Insights into UX approaches offered by the Data-Cube
Data-Cube’s three most important features are:
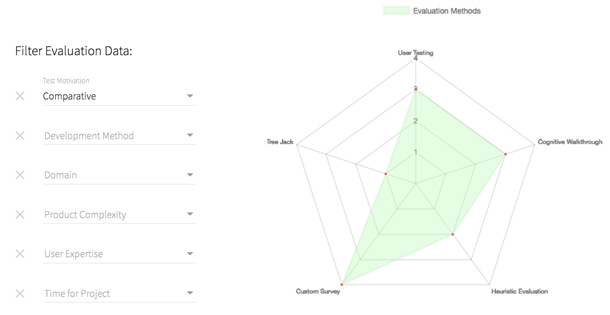
- Comparing different UX approaches from the collective database and performing a first analysis based on visualizations of the data as shown in Figure 3. Currently, only two types of graphical data representations are implemented. One graph shows how often each UX method has been used based on the filters selected, such as the product complexity. The second visualization shows a self-reported impact on redesign any given UX approach had on the product under evaluation. There are only two graphs at this moment, but since the project’s architecture is modular, additional representations of data can be easily implemented in future iterations.
- Selecting data sets and filtering metadata of usability evaluations to export is the second feature. Exporting data has been a highly requested feature since it allows for in-depth statistical analysis using other analysis tools.
- Finally, contributing data to the database is facilitated by reusing previously entered metadata from each user personally, and other users, as well. For example, if several usability evaluations are performed by a UX professional within the same project context, the Data-Cube app will store the metadata and suggest their reuse. Similarly, additional information, such as the application domain or user languages, are stored when first entered and then suggested to other users, depending on what they started to type.
This implementation of the Data-Cube app has been built based on a stack of modern web technologies including Angular, TypeScript, RxJS, Sass, Firebase, and Chart.js. Any suggestions, ideas, or even “pull requests” regarding the Data-Cube app are welcomed.
Going Forward
You can be involved in advancing the field of UX and assist with the continuing development of UXChart and Data-Cube by participating in the project and possible future workshops.
Tentative plans are to have the University of Texas at Austin School of Information host the repository. UX professionals, developers, and others interested in the technical aspects or future development of the Data-Cube app are invited to look at the open-source code on GitHub or contact Tobias Eisenschenk for possible collaborations.
Those interested in the UXChart should go to http://www.uxchart.com/ or contact Scott Butler.
If you are interested in the general idea of improved empiricism surrounding the UX practice, and/or participation in a potential second annual workshop on the Science of UX, contact Randolph Bias.
Workshop attendees
| Name | Affiliation |
| Randolph Bias | UT-Austin School of Information |
| Scott Butler | Ovo Studios |
| Tobias Eisenschenk | Technical University of Munich |
| Jacek Gwizdka | UT-Austin School of Information |
| Hans Huang | OpenText |
| Philip Kortum | Rice University |
| James R. Lewis | IBM |
| Eric Liu | AT&T |
| Stefania Mereu | Pearson |
| Stacy Michaelsen | Pusher, Inc. |
| Barbara Millet | University of Miami |
| Brian Moon | Perigean Technologies |
| Eric Nordquist | UT-Austin School of Information |
| Michelle Peterson | Sentier Strategic Resources |
| Ed Pierce | Catalyst |
| Andrea Richeson | Trademark Media |
| Marian Sweeney-Dillon | AT&T |
| Eric Taylor | DataSense |
| Tom Tullis | Fidelity Investments |
| Yan Zhang | UT-Austin School of Information |