As part of a user interface design or user experience (UX) project, we—the researchers—walk through all the steps for generating great user experiences. We understand what people do, think, say, and feel. We generate lists of questions and move through different research methods to answer our specific questions. We gain a new perspective on a problem and identify an opportunity area for creating a meaningful and accessible design experience. And finally, we generate some great ideas within the opportunity area by collecting and aggregating the research data and turning them into actionable insights.
But how do we estimate the reliability and validity of our research data? Does a reliability estimator or a validity testing method find a place in our research plan among other elements such as the research objectives, participant screening criteria, research methods and their estimated timelines, and deliverables? Often the answer is no.
The definition of reliability is that the research results must be repeatable or reproducible. Other researchers must be able to conduct the same research under the same conditions and generate the same data. This will corroborate the findings and ensure that the project team working on the design will accept the ideas and the insights generated after research is conducted.
However, the merit of research is not determined by its reliability alone. It is the validity of a research plan that determines its overall usefulness and lends to the strength of the results. Validity refers to the degree to which a research method measures what it claims to measure. It is essential for a research method to be valid for its proper administration and interpretation.
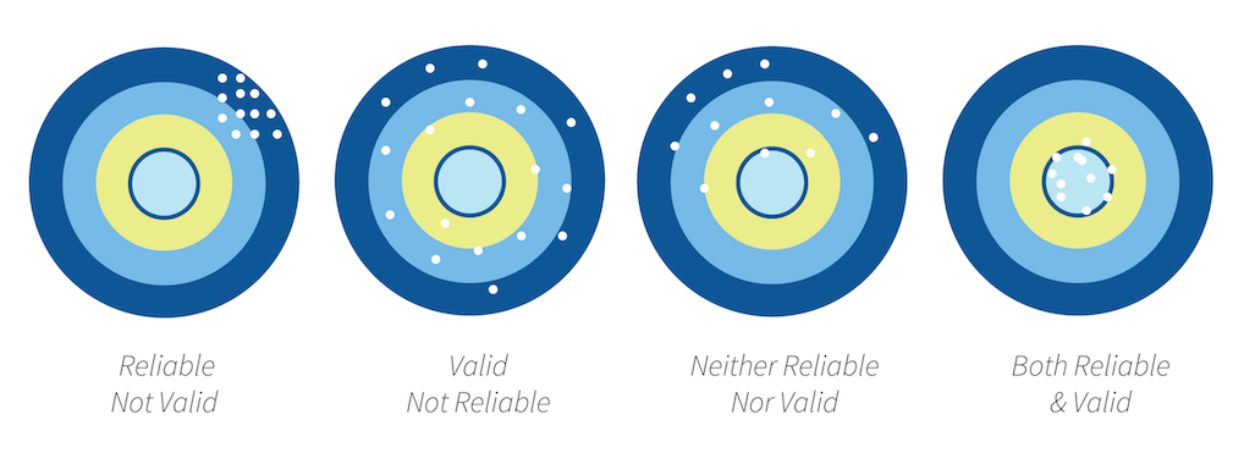
Figure 1. A visual representation of reliability and validity.
Both reliability and validity are necessary ingredients for determining the overall success of a research project (see Figure 1). Let us now see how we can estimate the reliability of our research findings and ensure the validity of the methods used in our research plan.
Methods of Estimating Reliability
The three methods that establish research findings as reliable are test-retest reliability, parallel forms reliability, and inter-rater reliability. Let us see which of these reliability estimators is best suited in different UX research scenarios.
Test-Retest Reliability
In the test-retest reliability method, the same test is repeated on the same set of research participants or test sample during two different time periods. The assumption behind this method is that there will be no substantial changes to the construct in question upon administration on separate occasions. The reliability coefficient in this case is measured by the correlation between the score obtained by the same participant on two administrations of the same test. The interval between the two tests is of critical value: the shorter the time gap, the higher the correlation value and vice versa. If a test is to be rated reliable, the scores that are attained on the first administration must be more or less equal to those obtained from the second test (a reliability coefficient greater than or equal to 0.7 on a scale from 0 to 1).
This reliability estimator is best suited when we use surveys or questionnaires as our research method. We identify a user group for each phase of the research plan and send a questionnaire to the group. Then we send the same questionnaire to the same group after a certain period of time has passed. And, at the end of the research phase, we compare the results of the two tests to validate our findings.
However, the test-retest reliability method does not come without a few limitations. One of the common challenges is the memory effect or the carryover effect. This can happen when the two test administrations or surveys take place within a short span of time. In such cases, the research participants tend to remember their responses, and as a result of which there can be prevalence of an artificial reliability coefficient. Another challenge of this method is that the same set of research participants might not be available for the retest. Finally, because the nature of our UX research is to measure people’s attitudes and feelings, responses genuinely can change over time; this would result in a low reliability coefficient, but may not indicate unreliable results.
Parallel Forms Reliability
The method of parallel forms reliability provides one of the most rigorous assessments of reliability in UX research. Also known as the equivalent forms reliability, this method compares two equivalent forms of a test that measure the same attribute. This reliability estimator is best suited when we include a long list of questions in our research plan and then split the questions into two equivalent sets. For example, we do two sets of user interviews or two sets of contextual inquiries with the same sample of people and ask different questions during the two sessions. After research is complete, we compare the data generated from both sets of user interviews or sets of the contextual inquiries.
Generally, the two tests are conducted on the same group of participants on the same day. In such cases, the only sources of variation in the reliability value are random errors and the difference between the forms of the test. On the other hand, when the tests are conducted at different times, errors associated with time sampling are also included in the estimate of reliability.
As with the test-retest reliability method, we are testing the same subjects twice which can be challenging when we are dealing with a low budget allocated to the research, non-availability of the same set of participants who are measured on two different occasions, and a short time span of a project.
Inter-Rater Reliability
Inter-rater reliability is a measure of reliability used to assess the degree to which different researchers agree in their assessment decisions. Because human observers do not necessarily interpret the answers to a research question the same way, this reliability estimator should be applied when the research method involves observation, field studies, or contextual inquiry. Researchers may disagree as to how well certain responses demonstrate a participant’s or a user’s as-is scenario, including pain points and opportunities for improvement. However, this issue can be mitigated by creating scorecards and training test observers so all people responsible for scoring are using an objective, mutually agreed upon set of measures.
Depending on the research method(s) employed, we should include at least one of the above reliability metrics in the research plan of every project.
Methods of Ensuring Validity
Validity also is an important aspect in research because it helps to establish the credibility or usefulness of our findings. For determining the validity of a research method, it must be compared with some ideal independent measure or criteria. The correlation coefficient computed between the research method and an ideal criterion is known as the validity coefficient (which ranges from 0 to 1 like other correlation coefficients). Correlation coefficients can be measured only when our research results are in numbers rather than words or concepts. Here are some measures of validity that we can use without calculating coefficients.
Face Validity
Face validity means a research method appears “on its face” to measure the construct or attribute of interest. Each research objective or question is scrutinized and modified until the researcher is satisfied that it is an accurate measure of the desired research attribute. The determination of face validity is based on the subjective opinion of the researcher.
Content Validity
Content validity is a non-statistical type of validity in which the content of a research plan is assessed to ascertain whether it includes all of the attributes that are intended to be measured. When the objectives or questions included in the research plan represent the entire range of possible items the research should cover, the research can be claimed as having content validity.
For example, if a researcher wants to develop a plan for defining the task flow of an application, then they should identify all of the elements included in the experience of launching and using the application. This can include setup and configuration, the speed of launch, the welcome screen, a comprehensible and user-friendly interface, options to restore and reset the application to its default state, and options to save the current state of the application and close it. The researcher should then create a test script or discussion guide to uncover all of the steps in the flow.
Construct Validity
The construct validity approach gauges how well a test measures the concepts or attributes it is designed to measure. In the social sciences, this can include subjective constructs like emotional maturity, test readiness, or relationship outcomes. Luckily for us, when this method is applied to A/B testing or other forms of usability testing, we can use measures such as time on task or number of clicks to measure our constructs. If our test hypothesis states that increased time on task leads to decreased satisfaction with an app, we can record time on task objectively. These data can be compared against one another in A/B testing or against pre- and post-test analytics in usability testing. They also can be measured against industry trends and norms. Time on task is an objective construct against which to measure our test validity.
Best Practices to Create a Foolproof Research Plan
Reliability and validity are central issues in every research project. Perfect reliability and validity are very difficult to achieve. However, we can ensure the maximum reliability and validity of our research plan by adhering to the following best practices:
- We should ensure that the goals and objectives of the research are clearly defined and operationalized.
- We should pair up the most appropriate research method with our goals and objectives.
- We should review the research objectives and questions with a subject-matter expert to obtain feedback from an outside party who is less invested in the project.
- We should compare our measures with other measures or data that may be available.
- We should eliminate the threats that can pose a challenge to the reliability and validity of our research, for example, selection bias, experimenter bias, and generalization.
Reliable and valid research results help us gain buy-in for the deliverables and project solutions that come next. And, by providing statistically significant numbers to back our research, we hopefully can convince those skeptical of our process to fund these essential UX steps.